
En un estudio reciente publicado en la revista Medicina digital NPJLos investigadores utilizaron el conjunto de datos de acelerómetro a gran escala del Biobanco del Reino Unido, que consta de datos sin etiquetar de 700.000 días-persona, para construir modelos para monitorear los niveles de actividad física con mayor precisión y generalización.
Para estudiar: Aprendizaje autosupervisado para el reconocimiento de la actividad humana utilizando 700.000 días-persona de datos portátiles. Crédito de la imagen: sutadimages/Shutterstock
Abajo
El campo de la atención médica ha experimentado un rápido aumento en el desarrollo y uso de dispositivos portátiles con sensores que pueden usarse para monitorear el bienestar y el estado físico, el monitoreo remoto de pacientes, ensayos clínicos que requieren datos en tiempo real, detección temprana, manejo de enfermedades, medicina personalizada y realizar estudios de salud a gran escala. Estos dispositivos proporcionan métricas resumidas sobre movimiento, calidad del sueño, recuento de pasos, ritmo y tiempo sedentario. Sin embargo, se necesitan algoritmos fiables para obtener información sobre la actividad humana a partir de los datos recopilados por el sensor.
Aunque campos como el procesamiento del lenguaje natural y la visión por computadora han avanzado significativamente debido a la disponibilidad de datos excedentes para entrenar estos modelos de aprendizaje, la escasez de conjuntos de datos a gran escala que puedan usarse para entrenar algoritmos ha restringido el progreso en el desarrollo de modelos que sean confiables y Reconocer con precisión la actividad humana. La falta de datos suficientes para entrenar estos modelos también ha confundido los hallazgos sobre los modelos de aprendizaje profundo, lo que sugiere que los modelos de aprendizaje profundo no funcionan mejor que los métodos convencionales, como las estadísticas simples.
Sobre el estudio
En el estudio actual, los investigadores utilizaron el conjunto de datos del acelerómetro del Biobanco del Reino Unido para entrenar modelos de aprendizaje profundo para reconocer la actividad física con precisión. UK Biobank llevó a cabo un estudio con acelerómetro a gran escala en el que se reclutó a casi medio millón de participantes. Más de cien mil de estos participantes llevaron un acelerómetro en su muñeca durante una semana en su entorno natural, a diferencia del entorno de un laboratorio. Esto proporcionó aproximadamente 700.000 días-persona de datos de movimiento humano en vida libre.
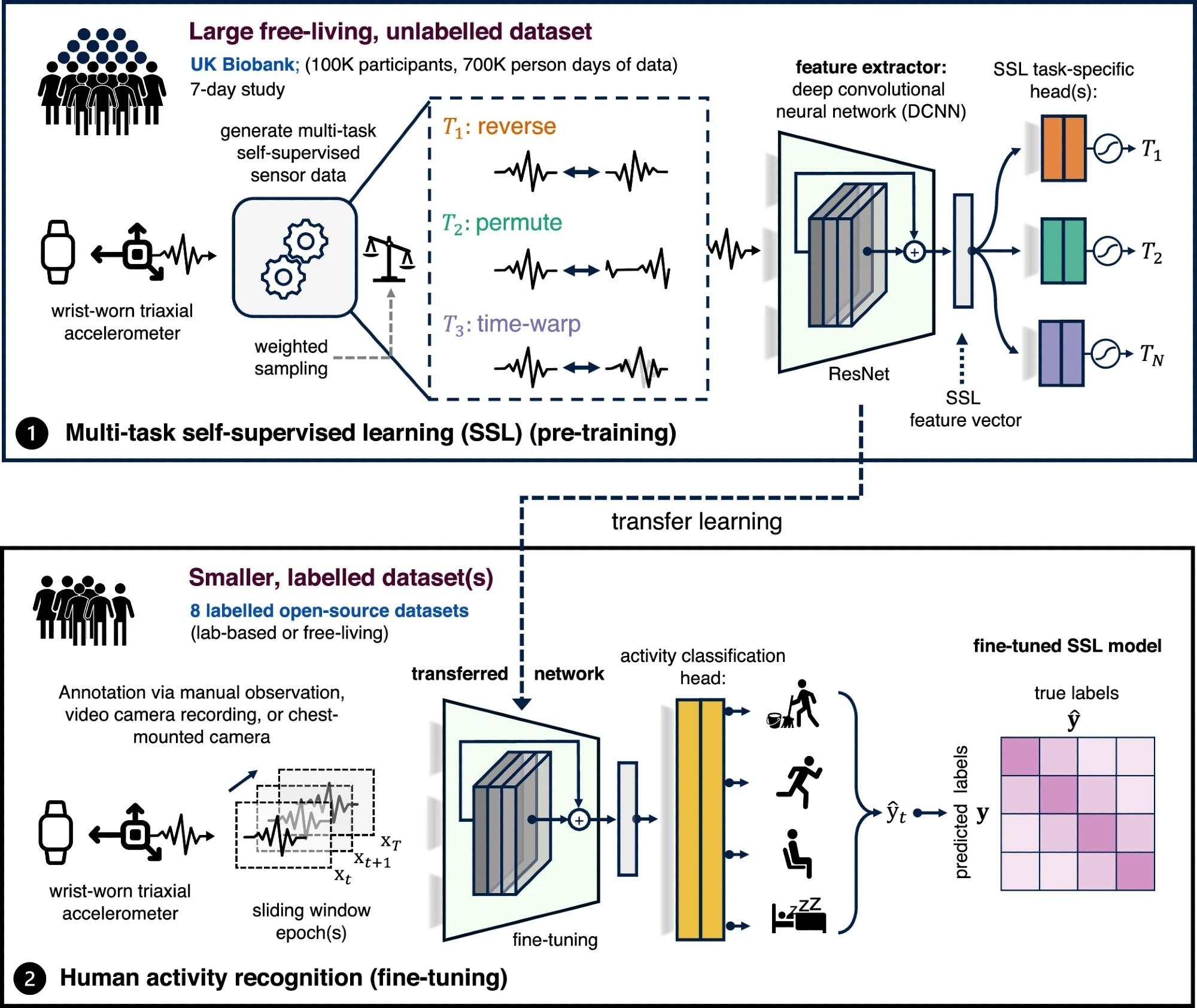 Descripción general del proceso de aprendizaje autosupervisado propuesto. El paso 1 implica el aprendizaje autosupervisado de múltiples tareas en 700.000 días-persona de datos del Biobanco del Reino Unido. En el paso 2, evaluamos la utilidad de la red previamente capacitada en ocho puntos de referencia de reconocimiento de la actividad humana a través del aprendizaje por transferencia.
Descripción general del proceso de aprendizaje autosupervisado propuesto. El paso 1 implica el aprendizaje autosupervisado de múltiples tareas en 700.000 días-persona de datos del Biobanco del Reino Unido. En el paso 2, evaluamos la utilidad de la red previamente capacitada en ocho puntos de referencia de reconocimiento de la actividad humana a través del aprendizaje por transferencia.
Los investigadores utilizaron un enfoque de aprendizaje autosupervisado, que se ha utilizado con éxito en ejemplos como transformadores generativos previamente entrenados o GPT. Estudios recientes han utilizado numerosos enfoques de aprendizaje autosupervisado, como la reconstrucción enmascarada, la autosupervisión multitarea, el arranque y el aprendizaje contrastivo para examinar el análisis de datos de sensores portátiles. El presente estudio aplicó el método de autosupervisión multitarea al gran conjunto de datos del Biobanco del Reino Unido para mostrar cómo un modelo previamente entrenado puede generalizarse a una amplia gama de conjuntos de datos basados en actividades con importancia clínica y sanitaria.
El método de aprendizaje de autosupervisión multitarea se aplicó por primera vez al conjunto de datos del acelerómetro a gran escala del Biobanco del Reino Unido para entrenar la red neuronal convolucional profunda. Posteriormente, se utilizaron ocho conjuntos de datos de referencia para evaluar el rendimiento de la red neuronal previamente entrenada y evaluar la calidad de la representación en diferentes poblaciones y tipos de actividades.
Se utilizaron conjuntos de datos etiquetados para evaluar el éxito del modelo en el aprendizaje por transferencia. Además, el estudio también utilizó un enfoque de muestreo ponderado para superar el problema de los períodos de poco tráfico sin información. Los datos del mundo real recopilados a partir de sensores de movimiento tienen períodos de inactividad y dichas señales estáticas no cambian durante la transformación, lo que presenta problemas para las tareas de aprendizaje autosupervisadas. Por lo tanto, para mejorar la convergencia y estabilidad del proceso de entrenamiento, los investigadores aplicaron un enfoque de muestreo ponderado en el que las ventanas de datos se muestrearon proporcionalmente y se utilizó una desviación estándar de estas muestras para el análisis.
Resultados
Los resultados mostraron que cuando los modelos entrenados en este estudio se probaron en ocho conjuntos de datos de referencia, superaron las líneas de base con una mejora relativa mediana del 24,4%. Además, el modelo se puede generalizar a una amplia gama de dispositivos de detección de movimiento, entornos residenciales, cohortes y conjuntos de datos externos.
El método de preentrenamiento de autosupervisión multitarea también ha demostrado ser eficaz para mejorar el reconocimiento posterior de la actividad humana, incluso en pequeños conjuntos de datos sin etiquetar. El preentrenamiento autosupervisado también podría funcionar mejor que el método supervisado.
Los investigadores afirmaron que este estudio demostró que el método de aprendizaje de autosupervisión multitarea se puede aplicar a conjuntos de datos de sensores portátiles y construir modelos de reconocimiento de actividad precisos y generalizables utilizando algoritmos de aprendizaje profundo.
El equipo de investigación también lanzó los modelos previamente entrenados a la comunidad de investigación que trabaja en salud digital para que se pudieran construir modelos de alto rendimiento sobre ellos para su uso en otros dominios que involucran datos etiquetados limitados.
Conclusiones
En resumen, el estudio utilizó un conjunto de datos a gran escala sin etiquetar del Biobanco del Reino Unido que consta de datos de acelerómetro para entrenar previamente modelos de aprendizaje profundo mediante un enfoque autosupervisado. Estos modelos previamente entrenados superaron los niveles básicos al analizar con precisión los datos de los sensores de movimiento en conjuntos de datos que varían según las cohortes, los dispositivos sensores y los entornos de vida. Los investigadores creen que estos modelos pueden construirse y utilizarse en diversos escenarios que impliquen cantidades limitadas de datos etiquetados.
Referencia del diario:
- Yuan, H., Chan, S., Creagh, A. P., Tong, C., Acquah, A., Clifton, D. A. y Doherty, A. (2024). Aprendizaje autosupervisado para el reconocimiento de la actividad humana utilizando 700.000 días-persona de datos portátiles. Npj Medicina Digital7(1), 91. DOI: 10.1038/s41746024010623, https://www.nature.com/articles/s41746-024-01062-3

/cloudfront-ap-southeast-2.images.arcpublishing.com/nzme/N7LQHXJ6ZQI26ZKQ2N3FFYO5KI.jpg "El entrenador personal revela el momento en que rompió después de que el cliente llegara a lo impensable.")


