Investigadores de CMU presentan TriForce: un sistema de inteligencia artificial de decodificación especulativa jerárquica que es escalable para la generación de secuencias largas


Con la implementación generalizada de modelos de lenguajes grandes (LLM) para la generación de contenido de formato largo, existe una necesidad creciente de un soporte eficiente para la inferencia de cadenas largas. Sin embargo, la caché de valores clave (KV), crucial para evitar recálculos, se ha convertido en un cuello de botella crítico, cuyo tamaño aumenta linealmente con la longitud de la secuencia. La naturaleza autorregresiva de los LLM requiere cargar toda la caché KV para cada token generado, lo que genera una baja utilización del núcleo computacional y una alta latencia. Aunque se han propuesto métodos de compresión, a menudo comprometen la calidad de la generación. Los LLM como GPT-4, Gemini y LWM están ganando importancia en aplicaciones como chatbots, generación de conocimientos y análisis financiero. Sin embargo, servir estos LLM de manera eficiente sigue siendo un desafío debido a la naturaleza autorregresiva y al creciente consumo de memoria de la caché KV.
Las metodologías anteriores proponen estrategias de desalojo de caché KV para reducir el consumo de memoria de la caché KV descartando selectivamente pares según las políticas de desalojo. Esto permite que los modelos funcionen con un presupuesto de caché limitado. Sin embargo, estas estrategias enfrentan desafíos debido a la posible pérdida de información, lo que genera problemas como alucinaciones e incoherencia contextual, particularmente en contextos prolongados. La decodificación especulativa, que implica el uso de un modelo scratch liviano para predecir los próximos tokens, se introdujo para acelerar la inferencia de LLM y al mismo tiempo preservar la salida del modelo. Sin embargo, implementar esto para la generación de secuencias largas presenta desafíos, incluida la necesidad de un cálculo sustancial para entrenar modelos preliminares y el riesgo de un rendimiento especulativo deficiente, especialmente con métodos existentes no entrenados, como las estrategias de desalojo de caché KV.
Investigadores de la Universidad Carnegie Mellon y Meta AI (FAIR) presentes Trifuerza, un sistema de decodificación especulativo jerárquico diseñado para la generación escalable de secuencias largas. TriForce utiliza los pesos del modelo original y la caché KV dispersa dinámica mediante la recuperación como modelo inicial, sirviendo como una capa intermedia en la jerarquía. Mantener el caché completo permite una selección superior del caché KV utilizando un diseño basado en recuperación, caracterizado por no tener pérdidas en comparación con los métodos basados en desalojo, como StreamingLLM y H2O. El sistema jerárquico aborda los cuellos de botella de la memoria dual al combinar un modelo liviano con un caché StreamingLLM para la especulación temprana con el fin de reducir la latencia de extracción y acelerar la inferencia de un extremo a otro.
TriForce presenta un sistema de decodificación especulativa jerárquica con selección de caché KV basada en recuperación. El sistema jerárquico aborda dos cuellos de botella, aumentando la aceleración. El diseño basado en recuperación segmenta la caché KV y resalta la información relevante. Los modelos livianos con caché StreamingLLM aceleran la especulación inicial y reducen la latencia de dibujo. TriForce utiliza pesos de modelo y caché KV para aumentar la velocidad de inferencia LLM para secuencias largas. La implementación utiliza CUDA Transformers, FlashAttention y gráficos PyTorch, manteniendo la escasez de capas completa y minimizando la sobrecarga de inicialización del kernel.

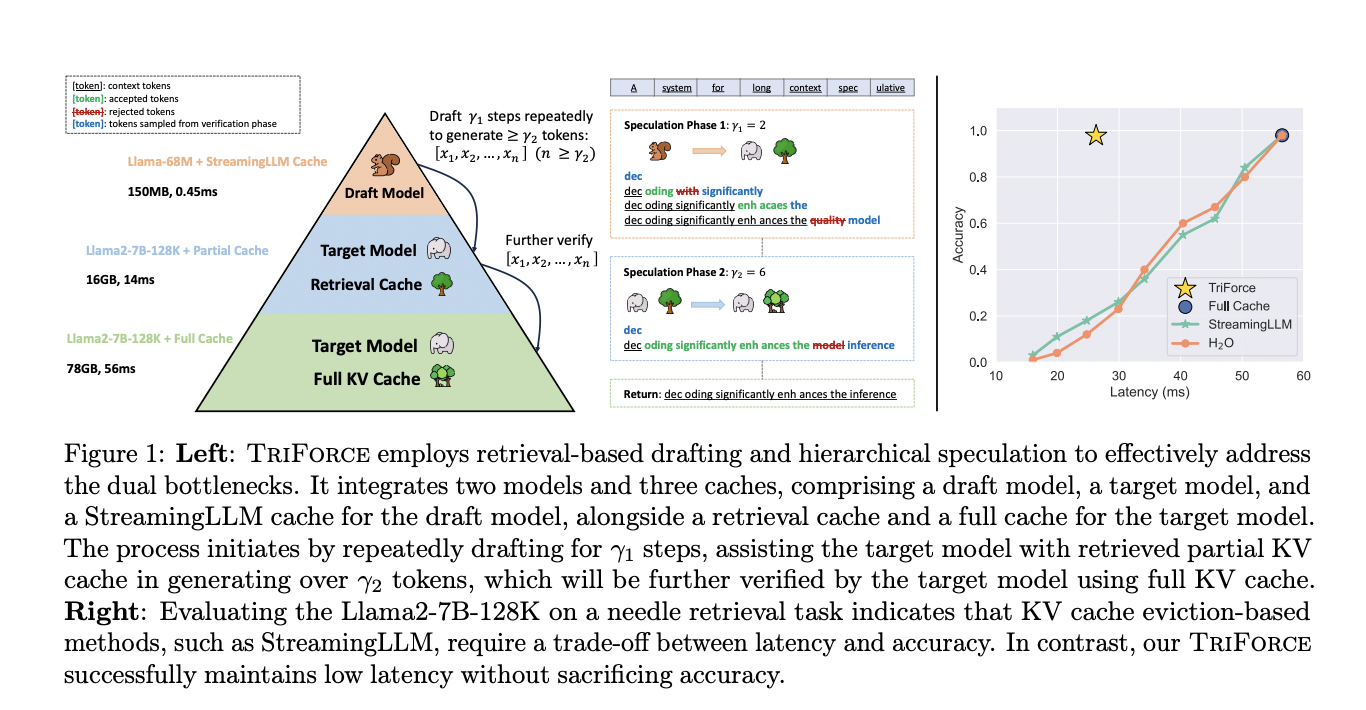
La evaluación TriForce revela importantes aceleraciones, hasta 2,31× con caché 4K KV para Llama2-7B128K en chip. La descarga de GPU de consumo logra una eficiencia notable, especialmente con Llama2-13B-128K en dos GPU RTX 4090, 7,94 veces más rápido que los sistemas optimizados. Llama2-7B-128K con TriForce opera a 0,108 s/token, la mitad de la velocidad de las líneas de base autorregresivas en A100. La inferencia por lotes también se beneficia, logrando una aceleración de 1,9 veces para un tamaño de lote de seis, cada uno con contextos de 19K.

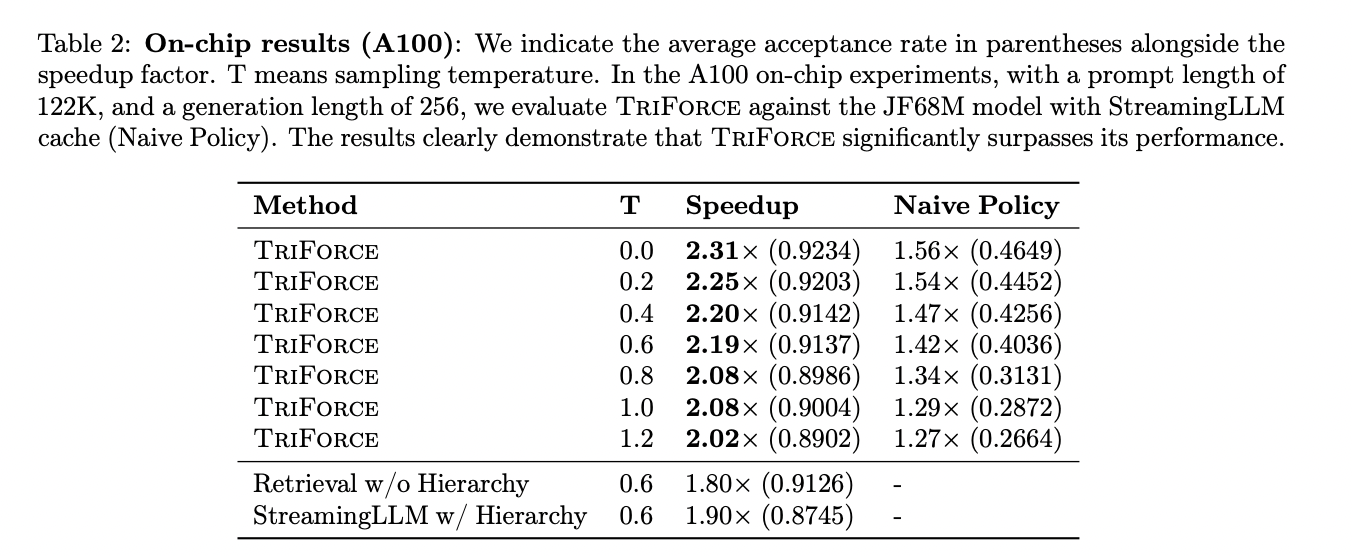
Para concluir, este trabajo presenta TriForce, un sistema de decodificación especulativa jerárquica destinado a servir eficientemente a los LLM en contextos largos. TriForce resuelve los cuellos de botella de caché KV duales y los pesos de los modelos, lo que genera aceleraciones significativas, que incluyen hasta 2,31 × en las GPU A100 y un extraordinario 7,78 × en las GPU RTX 4090. TriForce logra 0,108 s/token, la mitad de la velocidad de referencia autorregresiva en el A100. En comparación con DeepSpeed-Zero-Inference, TriForce en una sola GPU RTX 4090 es 4,86 veces más rápido y logra una aceleración de 1,9 veces con lotes grandes, lo que demuestra su potencial para revolucionar el servicio de modelos de contexto largo.
Revisar la Papel. Todo el crédito por esta investigación va a los investigadores de este proyecto. Además, no olvides seguirnos en Gorjeo. Únete a nuestro Canal de telegramas, canal de discordiaEs LinkedIn Grarriba.
Si te gusta nuestro trabajo, te encantará el nuestro. Del Boletín de noticias..
No olvides unirte a nuestro Subreddit de 40k+ML
Para asociación de contenido, por favor Llene este formulario aquí..


Asjad es consultor interno en Marktechpost. Está cursando B.Tech en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en la atención sanitaria.




