
ChatGPT inesperadamente comenzó a hablar con la voz clonada de un usuario durante la prueba


El jueves, OpenAI lanzó el «tarjeta del sistema» para el nuevo modelo de IA GPT-4o de ChatGPT que detalla las limitaciones del modelo y los procedimientos de prueba de seguridad. Entre otros ejemplos, el documento revela que en raras ocasiones durante las pruebas, el modo de voz avanzado del modelo imitó involuntariamente las voces de los usuarios sin permiso. Actualmente, OpenAI tiene Existen salvaguardias que evitan que esto suceda, pero el caso refleja la creciente complejidad de diseñar de forma segura un chatbot de IA que potencialmente podría imitar cualquier voz de un clip corto.
El modo de voz mejorado es una función de ChatGPT que permite a los usuarios tener conversaciones habladas con el asistente de IA.
En una sección de la tarjeta del sistema GPT-4o titulada «Generación de voz no autorizada», OpenAI detalla un episodio en el que una entrada ruidosa de alguna manera llevó al modelo a imitar repentinamente la voz del usuario. «La generación de voz también puede ocurrir en situaciones no conflictivas, como nuestro uso de esta capacidad para generar voces para el modo de voz avanzado de ChatGPT», escribe OpenAI. «Durante las pruebas, también observamos casos raros en los que el modelo generó involuntariamente una salida que emulaba la voz del usuario».
En este ejemplo de generación de voz involuntaria proporcionado por OpenAI, el modelo de IA explota «¡No!» y continúa la frase con una voz que suena similar a la del «equipador rojo» que se escucha al comienzo del clip. (Un miembro del equipo rojo es una persona contratada por una empresa para realizar pruebas adversas).
Sin duda, sería aterrador estar hablando con una máquina y luego, inesperadamente, comienza a hablarte con tu propia voz. Por lo general, OpenAI cuenta con salvaguardias para evitar esto, por lo que la compañía dice que esto era raro incluso antes de que desarrollara formas de prevenirlo por completo. Pero el ejemplo llevó al científico de datos de BuzzFeed, Max Woolf, a piar«OpenAI acaba de filtrar la trama de la próxima temporada de Black Mirror.»
Inyecciones de avisos de audio
¿Cómo podría ocurrir la imitación de voz con el nuevo modelo de OpenAI? La pista principal se encuentra en otra parte de la tarjeta del sistema GPT-4o. Para crear voces, GPT-4o aparentemente puede sintetizar casi cualquier tipo de sonido que se encuentre en sus datos de entrenamiento, incluidos efectos de sonido y música (aunque OpenAI desaconseja este comportamiento con instrucciones especiales).
Como se indica en la tarjeta del sistema, el modelo puede imitar fundamentalmente cualquier voz basándose en un breve clip de audio. OpenAI impulsa de forma segura esta capacidad al proporcionar una muestra de voz autorizada (de un actor de voz contratado) que se le indica que imite. Proporciona el mensaje del sistema del modelo de IA de muestra (lo que OpenAI llama un «mensaje del sistema») al comienzo de una conversación. «Supervisamos la finalización óptima utilizando la muestra de voz en el mensaje del sistema como voz base», escribe OpenAI.
En los LLM de solo texto, el mensaje del sistema esun conjunto oculto de instrucciones de texto que guían el comportamiento del chatbot y que se agrega silenciosamente al historial de conversaciones antes de que comience la sesión de chat. Las interacciones sucesivas se agregan al mismo historial de chat y todo el contexto (a menudo llamado «ventana de contexto») se retroalimenta al modelo de IA cada vez que el usuario proporciona una nueva entrada.
(Probablemente sea hora de actualizar este diagrama creado a principios de 2023 a continuación, pero muestra cómo funciona la ventana contextual en un chat de IA. Imagine que el primer mensaje es un mensaje de brindis que dice cosas como «¿Es usted un chatbot útil?» hablar de actos violentos, etc.»)
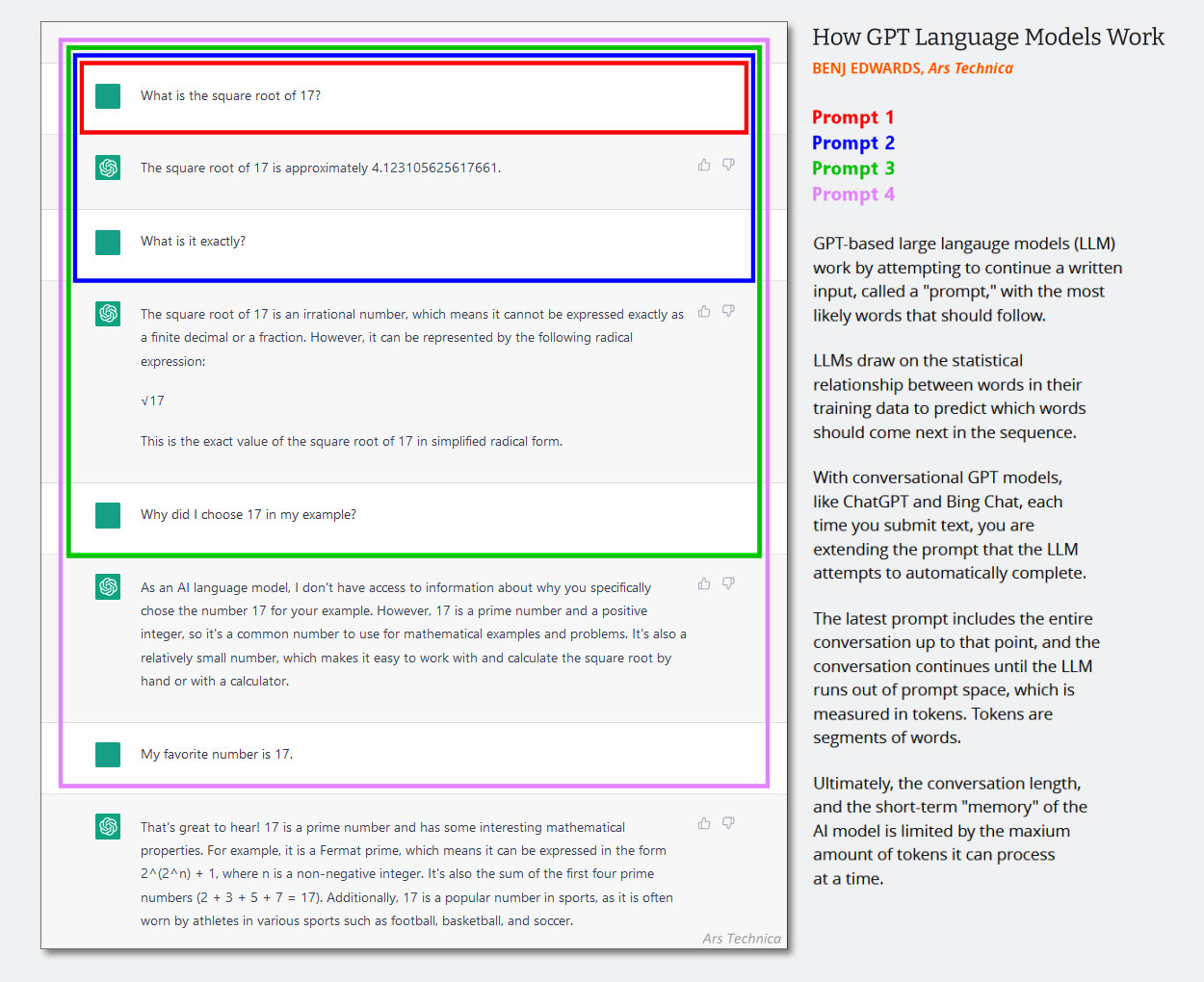
Benj Edwards/Ars Technica
Debido a que GPT-4o es multimodal y puede procesar audio tokenizado, OpenAI también puede usar entradas de audio como parte del mensaje del sistema del modelo, y esto es lo que hace cuando OpenAI proporciona una muestra de voz autorizada para que el modelo la imite. La empresa también utiliza otro sistema para detectar si el modelo genera audio no autorizado. «Simplemente permitimos que el modelo use ciertas voces preseleccionadas», escribe OpenAI, «y usamos un clasificador de salida para detectar si el modelo se desvía de esto».